WHY要有残差网络
首先,当网络发生退化时,意味着随着网络层数的增加,模型的性能并没有相应地提高,甚至可能变得更差。这通常是由于梯度消失、梯度爆炸或者模型优化难度增加导致的。在这种情况下,浅层的网络由于模型复杂度较低,可能更容易优化,因此能够达到更好的训练效果。
接下来,如果我们能够将低层的特征有效地传递到高层,那么高层网络就有可能利用这些有用的特征来提高性能。这是因为在深度学习中,低层网络通常学习一些基本的、通用的特征(如边缘、纹理等),而高层网络则在此基础上学习更复杂的特征。如果高层网络能够重用这些低层的特征,那么它就有可能达到甚至超过浅层网络的性能。
以VGG-100和VGG-16为例,假设我们在VGG-100的第98层和第14层之间添加一条直接映射(Identity Mapping)。这意味着第98层的输出将包含第14层的输出作为其一部分。如果这条直接映射能够有效地传递有用的特征,并且高层网络能够有效地利用这些特征,那么VGG-100的性能理论上应该至少与VGG-16相当,甚至可能更好。
然而,需要注意的是,直接映射并不意味着简单地复制和粘贴特征。它需要以一种有效的方式将低层特征整合到高层网络中,以确保高层网络能够充分利用这些特征。此外,还需要考虑如何平衡新旧特征之间的关系,以及如何处理特征维度不匹配等问题。
在实际应用中,直接映射的策略已经在一些深度学习架构中得到了应用,如残差网络(ResNet)和密集连接网络(DenseNet)。这些网络通过引入残差块或密集连接来实现直接映射,从而有效地缓解了网络退化的问题,并提高了模型的性能。
高层网络
在一个神经网络中,离输入层更远的网络层通常被称为“深层网络”或“高层网络”,因为它们在网络中的位置更深或更靠近网络的中间部分,而不是直接与输出层相连。这些深层网络通常包括多个隐藏层,并且在网络的层次结构中扮演重要的角色,用于提取更加抽象和高级的特征信息。
一个神经网络的层次结构通常包括输入层、多个隐藏层(包括深层网络)和输出层。深层网络在隐藏层中间位置,远离输入层但不是靠近输出层,因为深层网络通常在多层神经网络的结构中处于中间位置。
因此,深层网络位于输入层和输出层之间,通过多个隐藏层处理输入数据,逐步提取和学习特征,最终为输出层提供经过多次非线性变换后的表示以完成具体任务。深度学习模型的深度通常指的是隐藏层的层数,而深层网络则是指包含多个隐藏层的部分。
高层网络(即深层网络)在深度学习中具有以下特点:
多层结构:高层网络由多个隐藏层组成,每一层都包含大量的神经元。通过多层结构,网络可以学习和表示更加复杂和抽象的特征。
层间连接:不同层之间的神经元相互连接,信息逐层传递。每一层的输出作为下一层的输入,通过层间连接实现特征的组合和抽象。
特征提取:高层网络可以通过多个隐藏层逐步提取数据中的特征信息,从低级特征到高级特征的逐渐抽象过程有助于网络学习更深层次的表示。
表征学习:通过深度学习,高层网络可以自动学习表示数据的特征,而无需手工设计特征提取器。这种表征学习的方式能够更好地适应不同类型的数据和任务。
非线性变换:高层网络通过激活函数引入非线性变换,使网络能够学习和表示更加复杂的函数关系。非线性激活函数如ReLU、Sigmoid等有助于网络学习非线性模式。
端对端学习:高层网络支持端对端学习,即从原始输入数据端到最终输出结果端的全过程训练。这种端对端学习能够更好地优化整个模型,提高模型的泛化能力和性能。
总的来说,高层网络的特点包括多层结构、特征提取、表征学习、非线性变换等,使得深度学习模型能够更好地适应和解决复杂的机器学习任务。
在深度神经网络中,一旦到达最深层级,通常会对网络进行一些操作,以降低网络的深度或减少参数数量,使接下来的层级逐渐变浅。这些操作包括:
降采样(Downsampling):通过池化操作(如最大池化或平均池化)或步长较大的卷积操作来减少特征图的宽度和高度,从而减少下一层的神经元数量。
特征合并(Feature Concatenation):将前几层提取的高级特征与浅层特征进行连接或拼接,使得网络在接下来层级中不需要再学习这些高级特征,从而减少网络的深度。
特征选择(Feature Selection):对于某些特征进行筛选或降维,只保留最重要的特征,可以通过降维技术(如主成分分析)来实现。
残差连接(Residual Connections):在残差网络(ResNet)中使用残差连接,使得深层网络可以通过跳过连接获得浅层网络的信息,从而减少深层网络的堆叠层数。
特征映射(Feature Mapping):通过对特征图进行逐层映射或抽取表示,可以将原始的深层特征映射到浅层网络中,减少网络的深度。
这些操作旨在提高网络的效率和泛化能力,避免深度过深导致的梯度消失、计算量增加和过拟合等问题。通过适当的操作,可以使深度神经网络在保持良好性能的同时,减少深度或层级,提高网络的训练效率和性能。
CNN中的底层、高层特征、上下文信息、多尺度
CNN中的底层、高层特征:
简短总结: 分类要求特征有较多的高级信息,回归(定位)要求特征包含更多的细节信息
图像的低层特征(对定位任务帮助大,我们可以想想比如轮廓信息都不准那怎么去良好定位):
图像底层特征指的是:轮廓、边缘、颜色、纹理、棱角和形状特征。
边缘和轮廓能反映图像内容;如果能对边缘和关键点进行可靠提取的话,很多视觉问题就基本上得到了解决。图像的低层的特征语义信息比较少,但越浅的层特征越细节(低级)且特征图分辨率大,所以位置信息很充足,目标位置准确。再从另一个方面讲,越浅层的特征感受野越小(每个像素点映射回原图的覆盖面积小),故用浅层特征图检测大目标时就有点像瞎子摸象的感觉效果并不好,因为光能看到象腿也不知道这是啥东西。当然对于小目标检测来说如果能利用足够的上下文信息也是有好处的!例如,通过只看图中的一个小目标所在的那个位置,人类甚至很难识别这些物体。然而,通过考虑到它位于天空中的背景,这个物体可以被识别为鸟类。因此,我们认为,解决这个问题的关键取决于我们如何将上下文作为额外信息来帮助检测小目标。
图像的高层特征也叫语义特征(高层特征即CNN中网络越深的层得到的特征,高层的特征包含很丰富的组合信息,象征着人对它的分辨能力,越高层越好分辨出是啥东西,如表征着类别啥的,对识别任务帮助大):
图像的高层语义特征值得是我们所能看的东西,比如对一张人脸提取低层特征我们可以提取到连的轮廓、鼻子、眼睛之类的,那么高层的特征就显示为一张人脸。高层的特征语义信息比较丰富,但是目标位置比较粗略。
愈深层特征包含的高层语义性愈强、分辨能力也愈强。我们把图像的视觉特征称为视觉空间 (visual space),把种类的语义信息称为语义空间 (semantic space)
上下文信息
做图像的,上下文特征是很常见的,其实上下文大概去理解就是图像中的每一个像素点不可能是孤立的,一个像素一定和周围像素是有一定的关系的,大量像素的互相联系才产生了图像中的各种物体,所以上下文特征就指像素以及周边像素的某种联系。
具体到图像语义分割,一般论文会说我们的XXX算法充分结合了上下文信息,意思也就是在判断某一个位置上的像素属于哪种类别的时候,不仅考察到该像素的灰度值,还充分考虑和它临近的像素。
然后上下文信息还分全局和局部,意思就是考虑全图不同范围内的像素和只考虑邻近的一些像素。
全局上下文信息 也可以理解为能够捕捉来自更多的不同尺度的上下文信息,不同尺度就是指不同感受野。
多尺度
个人感觉,多尺度 就是 你能看到的范围(看到尺度就理解为CNN的感受野就完事了!!!)。
图像中一个东西的尺度越大,就指距离越近相当于被放大了,那么给人感觉就越模糊。例如:
训练的时候,把图片缩放到不同大小输入给同一个网络,网络就能看到不一样大小范围的内容,缩放得分辨率越高就指尺度越大,因为对图中的某一个物体来讲就是被放大的感觉。然后就是因为缩放后,比如中间特征图上的某个像素点都只能看到原图3乘3的区域,可随着输入的图片尺度不一样,同样是看到的3乘3区域,但相对于整张图的范围也自然就不一样了,然后就叫做多尺度训练;好处是可以适应不同尺度的输入,泛化性好。
把一个特征层用由不同感受野的卷积核组成的网络层(例如SPP)处理,这层网络的同一个像素位置就能看到不同范围的上层特征,就叫做多尺度特征融合;好处是能考虑到不同范围的空间特征上下文(例如头发下面一般会有一张脸)。
把一个网络中不同深度的层做融合:浅层感受野小,分辨率大,能够处理并保存小尺度的几何特征;高层感受野大,分辨率小,能够处理并保存大尺度的语义特征。这也叫做多尺度特征融合;好处是能够将语义特征和几何特征进行融合(例如这块区域是头发,低分辨率图上的分界线一般是线状特征和非线状特征的边界)。
从信息论的角度讲,由于DPI(数据处理不等式)的存在,在前向传输的过程中,随着层数的加深,Feature Map包含的图像信息会逐层减少,而ResNet的直接映射的加入,保证了$l+1$层的网络一定比$l$层包含更多的图像信息。
解释
保证了$l+1$层的网络一定比l层包含更多的图像信息,这是因为直接映射(恒等映射)将前一层的信息无损地传递到了后一层,确保了信息的完整性。同时,由于残差部分的存在,网络可以学习输入和输出之间的差值,即残差。这个残差部分可能会引入一些新的、有用的特征或模式,这些特征或模式在之前的层中可能并不存在。这些新增的特征或模式会与直接映射的信息相结合,导致$l+1$层的信息量实际上比$l$层更多。
换句话说,直接映射保证了信息量的下限(即至少与前一层相同),而残差部分则有可能增加额外的信息量。因此,综合这两部分,$l+1$层的网络包含的信息量一定会比$l$层更多。这也是ResNet能够在增加网络深度的同时保持甚至提高性能的关键原因之一。
需要注意的是,这里的“更多”并不意味着绝对的信息量一定更大,而是指相对于前一层,后一层有可能包含更多的有用特征或模式。在实际应用中,还需要考虑其他因素,如网络的训练方式、数据集的质量等,来综合评估网络性能。基于这种使用直接映射来连接网络不同层直接的思想,残差网络应运而生。
残差网络
残差块
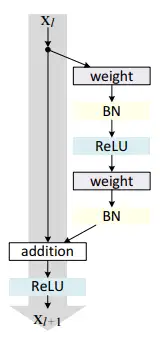
残差网络是由一系列残差块组成的(图1)。一个残差块可以用表示为:
$x_{l+1}=x_l+F(x_l,W_l)$

图1中的Weight在卷积网络中是指卷积操作,addition指的是单位加操作,即在卷积计算中的相加步骤。
卷积计算的4个步骤为反折、平移、相乘、相加。将两组数进行卷积后,变成第三组数,其中相加就是addition。
残差块分成两部分-直接映射部分和残差部分。
- $h(x_l)$是直接映射,反应在图1中是左边的曲线
- $F(x_l,W_l)$是残差部分,一般由两个或者三个卷积操作构成,即图1中右侧包含卷积的部分。
在卷积网络中,$x_l$可能和$x_{l+1}$的Feature Map的数量不一样,这时候就需要使用$1×1$卷积进行升维或者降维(图2)。

这时,残差块表示为:
$x_{l+1}=h(x_l)+F(x_l,W_l)$
其中$h(x_l)=W_l^{‘}x$。其中$W_l^{‘}$是$1×1$卷积操作,但是实验结果$1×1$卷积对模型性能提升有限,所以一般是在升维或者降维时才会使用。

一般,这种版本的残差块叫做resnet_v1,keras代码实现如下:
1 | def res_block_v1(x, input_filter, output_filter): |
这段代码定义了一个简单的残差块(residual block),用于构建残差神经网络(ResNet)中的一个基本单元。在这段代码中,res_block_v1函数接受输入特征x,输入的卷积核数量input_filter和输出的卷积核数量output_filter作为参数,然后构建一个残差块,并返回处理后的输出特征。
具体实现过程如下:
- 使用一个3x3大小的卷积核,输出通道数为
output_filter,步长为1,填充方式为’same’进行卷积操作,并接上BatchNormalization层和ReLU激活函数。 - 再次使用一个3x3大小的卷积核,输出通道数为
output_filter,步长为1,填充方式为’same’进行卷积操作,并接上BatchNormalization层。 - 根据输入卷积核数量和输出卷积核数量是否相等,判断是否需要进行维度加减变换,如果相等则直接将输入特征作为恒等映射(identity),否则使用1x1的卷积核进行维度变换。
- 将恒等映射和经过两次卷积操作的特征相加,得到残差连接。
- 对残差连接的结果进行ReLU激活函数操作,最终输出处理后的特征。
这段代码展示了如何实现一个简单的残差块,用于搭建深度残差神经网络,通过残差连接来解决深度神经网络训练中的梯度消失和梯度爆炸问题,帮助网络更好地训练和优化。
残差网络的搭建
残差网络的搭建分为两步:
- 使用VGG公式搭建Plain VGG网络
- 在Plain VGG的卷积网络之间插入Identity Mapping,注意需要升维或者降维的时候加入$1×1$卷积。
在实现过程中,一般是直接stack残差块的方式。1
2
3
4
5
6
7def resnet_v1(x):
x = Conv2D(kernel_size=(3,3), filters=16, strides=1, padding='same', activation='relu')(x)
x = res_block_v1(x, 16, 16)
x = res_block_v1(x, 16, 32)
x = Flatten()(x)
outputs = Dense(10, activation='softmax', kernel_initializer='he_normal')(x)
return outputs
为什么叫残差网络
在统计学中,残差和误差是非常容易混淆的两个概念。误差是衡量观测值和真实值之间的差距,残差是指预测值和观测值之间的差距。对于残差网络的命名原因,作者给出的解释是,网络的一层通常可以看做$y=H(x)$, 而残差网络的一个残差块可以表示为$H(x)=F(x)+x$,也就是$F(x)=H(x)-x$,在单位映射中,$y=x$便是观测值,而$H(x)$是预测值,所以$F(x)$便对应着残差,因此叫做残差网络。
略
将激活函数移动到残差部分可以提高模型的精度
该网络一般就在resnet_v2,keras实现如下:
1 | def res_block_v2(x, input_filter, output_filter): |



